K近邻算法:从原理到实践的完整指南
深入浅出地讲解K近邻算法的原理、实现与应用
K近邻算法:从原理到实践的完整指南
K近邻算法简介
K近邻算法(K-Nearest Neighbors, KNN)是一种简单而强大的监督学习算法。它的核心思想源于生活中的一个普遍现象:物以类聚,人以群分。具体到机器学习领域,它通过分析训练数据集中与待预测样本最相似的K个近邻样本,来预测新样本的属性。
算法原理
K近邻算法的工作原理可以通过以下步骤来理解:
特征空间:首先将所有数据点映射到特征空间中。每个数据点都可以用其特征值来表示其在这个空间中的位置。
距离计算:当需要对新样本进行预测时,算法会计算该样本与训练集中所有样本的距离。
K个近邻:选择距离最近的K个邻居。这里的K是一个预先设定的参数,它的选择会影响算法的预测结果。
决策规则:
- 对于分类问题:采用投票法,选择K个近邻中出现最多的类别作为预测结果
- 对于回归问题:计算K个近邻的目标值的平均值作为预测结果
常用的距离计算方法包括:
- 欧氏距离:最常用的距离度量,计算两点之间的直线距离
- 曼哈顿距离:计算两点在坐标轴方向上的距离之和
- 明可夫斯基距离:欧氏距离和曼哈顿距离的一般化形式
- 加权距离:根据距离远近对不同邻居赋予不同的权重
- 基于半径的距离:选择给定半径内的所有样本点作为近邻
算法特点
K近邻算法具有以下特点:
- 优点:
- 理论成熟,思想简单,易于理解和实现
- 无需训练过程,属于懒惰学习算法
- 对异常值不敏感
- 适用于多分类问题
- 缺点:
- 计算量大,预测时需要计算所有训练样本的距离
- 样本不平衡时效果不好
- 对特征数量敏感,维度灾难
- K值的选择需要经验
- 适用场景:
- 数据量相对较小
- 特征空间简单
- 样本分布均匀
- 需要快速建模验证的场景
实战示例
Scikit-Learn库为我们提供了完整的K近邻算法实现。主要包括:
KNeighborsRegressor:用于回归问题KNeighborsClassifier:用于分类问题RadiusNeighborsRegressor和RadiusNeighborsClassifier:基于半径的近邻算法
使用K近邻对花卉进行分类
我们将使用著名的鸢尾花(Iris)数据集来演示K近邻分类器的使用。该数据集包含三种不同品种鸢尾花的测量数据。
1
2
3
4
5
6
7
8
9
10
# 导入所需的库
import pandas as pd
from sklearn.datasets import load_iris
# 加载数据集并转换为DataFrame
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['class'] = iris.target
df['class name'] = iris.target_names[df['class']]
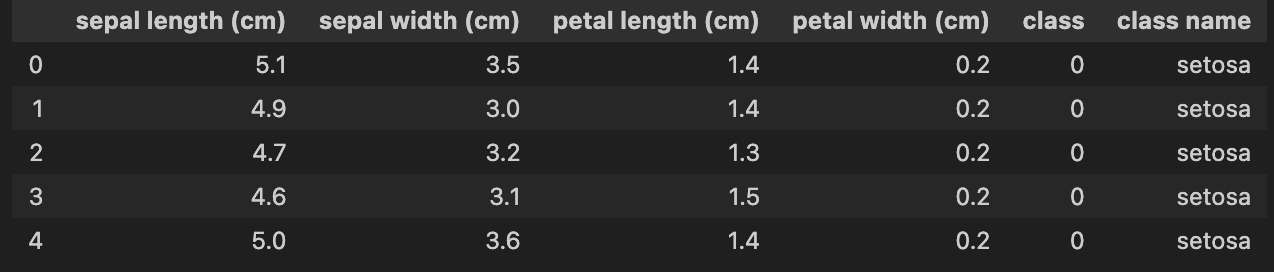
df.head()
接下来,我们需要将数据集分为训练集和测试集。这是机器学习中的一个标准步骤,目的是评估模型的泛化能力。
训练集和测试集的划分比例需要权衡:训练数据越多,模型学习的信息越充分;测试数据越多,模型评估的可靠性越高。这里我们采用常用的80/20比例。
1
2
3
4
5
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2)
现在我们来训练K近邻分类器:
1
2
3
4
5
6
7
from sklearn.neighbors import KNeighborsClassifier
# 创建并训练模型
knn = KNeighborsClassifier() # 默认k=5
# 调用fit方法使模型拟合到数据,从而完成对它的训练。
knn.fit(x_train, y_train)
K近邻算法的
fit方法执行速度很快,这是因为它实际上只是存储训练数据并构建用于快速检索的数据结构(如KD树),而不是传统意义上的”训练”过程。
让我们评估模型的性能:
1
2
3
# 在测试集上评估模型
score = knn.score(x_test, y_test)
print(f"模型准确率: {score:.2%}") # 输出:96.67%
我们还可以用训练好的模型来预测新的样本:
1
2
3
4
5
# 预测新样本的类别
y_pred = knn.predict([[5.1, 3.5, 1.4, 0.2]])
# 在 Scikit-Learn 中,我们可以通过调用predict方法来进行预测。结果0代表为山鸢尾,1代表为变色鸢尾,2代表为维吉尼亚鸢尾。
print(f"预测结果: {iris.target_names[y_pred[0]]}") # 输出:setosa
K近邻算法中K值的选择很重要,我们可以通过参数调整来优化模型:
1
2
# 使用10个近邻
knn = KNeighborsClassifier(n_neighbors=10)
本文由作者按照 CC BY 4.0 进行授权